Jan W. Amtrup
Computing Research Laboratory
Introduction
Meat, the Multilingual Environment for Advanced Translations, is the
underlying architecture of the Shiraz machine translation system. This
architecture is centered around the notion of a chart, capable of
storing partial and complete results
on a multitude of description levels, ranging from simple tokens, which
appear in the source text, to syntactic analyses and target language
output strings. The system operates on Unicode strings, complex typed
feature structures are used to encode linguistic knowledge and
intermediate results. The system consists of a number of modules which
can be configured to perform different tasks, from glossing a text to
full machine translation.
This report
describes some aspects of the architecture and gives an outline of the
modules involved in the translation from Persian to English. The
system is completely written in C++ and can be used both on Unix
machines or on PCs. We have also applied
Meat for translations from Korean, Japanese, Spanish,
Russian, Serbo-Croatian, and Turkish.
Charts for Shiraz
The central data structure within Shiraz is a chart, which is used to
store partial and completed results on all levels of linguistic
description. A Chart [Kay:80] is an acyclic,
directed graph of hypotheses about parts of a document. Vertices
correspond to points between words, edges denote words or descriptions
of a sequence of words. Charts are extremely suitable for the
representation of results within a natural language processing
system. They allow to separate the description of what needs to be
processed from the exact order in which actions are carried out, thus
allowing for a wide range of search and processing
strategies. Moreover, they remove redundancy since not only complete
results are stored, but also all partial results that arise during a
computation. These partial results can be reused in a larger context.
Shiraz uses several types of edges to distinguish between different
types and levels of description. Thus, the chart can not only be used
for a single purpose (say, syntactic parsing or generation), but it
stores all hypotheses on all levels. Internally, so-called tags are
used to mark edges as to what module they belong. In fact, the chart
used for Shiraz is a weaker version of the layered chart used in
[Amtrup:97], in that it does not support
hypergraphs or the distribution of modules to employ parallel processing.
Edges in the chart are annotated with complex typed feature
structures following [Carpenter:92]. Different types of feature
structures can be used to encode different aspects of liguistic
knowledge conveniently. We use an efficient implementation based on a
vector-oriented representation for feature structures.
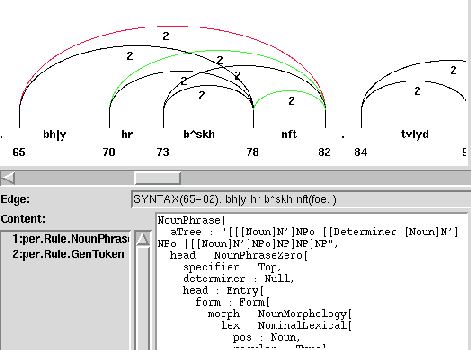
Figure 1 shows an image of a chart and some
of its edges. In the lower part of the image, part of a feature
structure is shown.
 |
|
Figure 1: A Chart and some edges
|
Components and the application definition
The Shiraz system is designed to fulfill different functions within a
natural language processing scenario. Two main requirements have to be
met:
- The core system must be capable of processing different languages,
probably using different scripts. Thus, Shiraz uses Unicode characters
to represent user data throughout. Strings within feature structures
are also Unicode.
- The system has to handle differents tasks. In the Persian case,
at least a glosser and a full translation system have to be supported.
The approach we chose in order to realize a configurable, flexible
system is a combination of extreme modularization and user-defined
application. Shiraz consists of currently 27 different modules. The
user is able to compose a sequence of modules in order to build a
complete application. Upon runtime, the system interprets the
application definition and executes the modules needed.
An application definition file defines
- A set of variable definitions, which can be used later on to save
on typing and to group things,
- A set of application definitions, which define which modules to
execute for which application, and
- A set of module definitions, which define the parameters for
individual modules.
A small excerpt from the Persian application definition file is shown
in figure 2. It exemplifies the composition of
modules to form a complete application, as well as the definition of
parameters, variables, and the incorporation of command-line parameters.
// Variable definitions
$RES=/home/mcm2/meat/per
// Global parameters
tangoModule = $(RES)/shiraz.mod
// An application
application lookup = Tokenizer($File=$1):PostTokenizer:MorphAnalyzer:
DictionaryLookup:DictionaryCompoundLookup:ChartViewer
// Sample module definitions
module Tokenizer {
class = Tokenizer
inputFile = /home/mcm/$File
encoding = UTF8
}
module MorphAnalyzer {
class = MorphAnalyzer
grammar = $(RES)/GenMorph.samba
rule = Morphology
type = chart
sourceTag = TOKEN
targetTag = MATOKEN
}
Figure 2: A sample application definition file
|
Components of the Shiraz system
In this section, we give a short overview of the main components that are
involved in constructing an English translation from a Persian
document. Using the mechanism just mentioned, an application is
defined as a sequence of modules which are executed one after the
other. The results of each component are gathered in the central chart
and can be used by any other component. The translation process can be
divided into five major steps:
- Reading and preparing the input text
- Morphological analysis and dictionary lookup
- Syntactic parsing
- Transfer
- Generation and preparation of the target language output
Preparing the input text
The first step in preparing the input text for a translation is
performed by a Tokenizer, which reads an input file and splits
this up into separate items such as words, punctuation, numbers
etc. The input file is usually not in ASCII format, but rather a code
conversion from some encoding to Unicode has to be performed. The
tokenizer is a generic Unicode tokenizer, it is not specialized for
any language.
For the Persian case, we also added a Posttokenizer. The
task of this component is to postprocess the Tokenizer output with
respect to some peculiarities of Persian. In particular, detached
affixes are again attached to their kernels.
Morphological analysis and dictionary
lookup
Then, in order to be able to perform dictionary lookup, the inflected
surface words need to be processed by a Morphological Analyzer. We use a finite
state transducer with feature structures formalism called Samba
[Zajac:98] to describe morphological
properties of words. Figure 3 shows a simple
rule that describes the suffix which marks the causative form of
Persian verbs. For more information see
the web report on
Persian Morphology.
CausativePastStem < GeneralRule;
CausativePastStem =
< RegularPresentStem
<"|n" "d">
[form.morph.infl: per.Form.VerbalInflection[
causative: True]]
>;
Figure 3: A simple morphological rule
|
The dictionary itself is based on citation forms. It contains
approx. 50000 entries. Dictionary Lookup takes the citation
forms generated by the morphological analyzer and uses them to access
lemma definitions in the lexicon. The inflectional information gained
by morphology is then unified with the dictionary entry, rendering a
rich description of the input word. For a more detailed description of
the structure of the lexicon, see the web report on
the Shiraz dictionary.
Compounding is taken care of in the Compound lookup
component. Here, we are not looking for individual words in the
dictionary, but rather take any sequence of words to find
compounds. The compound lookup procedure is based both on citation
forms and surface forms, since some compound parts are not words on
their own right. We do not record the internal structure of compounds in
the dictionary, but since Persian is a head-final language, we assume
that the last element in a compound carries the most important
inflectional information. The compound inherits this inflectional
information, if possible.
Syntactic Parsing
The parser employed in Shiraz is a unification-based, bidirectional
Chart parser. Figure 4 shows a simple syntax
rule for the composition of complex noun phrases. The rules are phrase
structure rules, and consist of a left hand side, which describes the
constituent being formed, and a right hand side, which describes which
subconstituents are used for the construction. Feature structures on
both sides allow to formulate restrictions and to build up
structure. The rules can be parametrized to allow for certain special
situations. First, they can be marked as non-recursive, in which case
they are not used to propose new categories more than once at the same
position. Second, they can be marked to perform dictionary lookup. If
this happens, the left hand side is considered to refer to a
dictionary entry and it is only constructed if there is an entry in
the dictionary which matches the citation form built.
complexNP = per.Rule.Rule[
lhs: per.Rule.NounPhrase[
head: #np1,
possessor: #np2],
rhs: <:
#np1= per.Rule.NounPhraseZero[
boundary: per.Type.FalseOrUndefined]
#np2= per.Rule.NounPhrase[
head: per.Entry.Entry[form.morph.lex.pos: per.Type.NounHeads]]
:>
];
Figure 4: A sample syntax rule
|
In the Shiraz system, we use three incarnations of the parser to
perform different tasks. You can think of this as having a grammar
with different levels, each of which is applied in sequence. These
incarnations are:
- The Auxiliary Verb Parser which is used to attach auxiliary
verbs to their main verb counterparts. In doing that, morphological
information is merged.
- The Light Verb Parser. Persian shows a large number of
light verbs, which are combinations of non-verbal words (Nouns,
Adjectives, etc.) with semantically poor verbs (most often ``do''). These
combinations have a non-compositional semantics, so they need to be
lexicalized. The light verb parser combines the individual parts of
a light verb and looks it up in the dictionary.
- Finally, the Syntax Parser is used to construct syntactic
constituents from individual words.
Transfer
The Transfer component is used to transform Persian syntactic
structures to their English counterparts. Currently, we are only
performing lexical transfer, i.e. the Persian morphological
information is mapped to English inflectional features. Like all
components within the Shiraz system, transfer is based on the chart
notion. Incorporating syntactic transfer will allow to reuse partial
translations within larger constructs (cf. [Amtrup:95]).
Generation and Surface Construction
Two components are involved in the final construction of English
surface strings: The Syntactic Generator creates English
fragments, and the Surface Generator searches for a suitable
path through the fragments.
Syntactic generation currently uses a simple method of linearization of
English words. There is no complex mechanism to generate surface
strings from syntactic descriptions. A sample rule for the generator
is shown in Figure 5.
np1 = [
structure: per.Rule.NounPhrase[
head: #1= Top,
relClause: #2= Top],
order: <: #1 #2 :>,
trigger: "relClause"
];
Figure 5: A sample generation rule
|
The rule demonstrates the three elements present in a generation
rule:
- The structure defines what kind of syntactic structure can be
handled by the rule.
- The order defines in which surface order the underlying parts
should be generated. Fixed strings can be inserted here as well,
e.g. to mark the possessor in English with an additional ``of''.
- The trigger restricts the application of rules. If present, then
the feature marked by the trigger path has to be non-empty in order
for the rule to be applicable.
Apart from constructing surface strings from syntactic
descriptions, a morphological generation procedure is performed during
this phase. Thus, English words are generated with correct inflection.
The surface generation, finally, chooses the best path through the
graph of generated English surface fragments and issues these as
output. In the future, we plan to use an English language model to
choose among the many possible surface strings. The string which is
ranked best by the model will be issued.
System Statistics
The system is completely written in C++ (with the exception of a small
Java applet used to render Persian script for the glosser). It
consists of approx. 27000 lines of code. It can be run on both Unix
platforms (using the Gnu compiler) and PCs running Windows NT (using
Visual C++). Translating a sentence of medium length and complexity
(i.e., ambiguity) takes between 8 and 15 seconds.
Conclusion
Shiraz is a machine translation system for translating Persian written
text into English. It is based on two main architectural foundations:
The use of a chart throughout the system, which allows an integrated
view on results created on all levels of linguistic description, and
the use of a complex typed feature structure formalism, which unifies
the view on the descriptions itself.
Apart from a major renovation (the system was written in a short
period of time, which led to some suboptimal solutions and left almost
no time for optimization), the main components that could be added are
a model of syntactic-semantic transfer and a more elaborate syntactic
generation.
References
 Amtrup, Jan W., 1995
Amtrup, Jan W., 1995- Chart-based Incremental Transfer
in Machine Translation. In Proceedings of the Sixth International
Conference on Theoretical and Methodological Issues in Machine Translation.
KU Leuven, July 1995, pp. 188-195.
Postscript, 8pp, 45k
-
Amtrup, Jan W., 1997
- Layered Charts for Speech
Translation. In Proceedings of the Seventh International
Conference on Theoretical and Methodological Issues in Machine
Translation, TMI '97,
Sante Fe, NM, Jul. 1997, pp. 192-199.
Postscript, 8pp, 44k
-
Carpenter, Bob, 1992
- The Logic of Typed Feature Structures.
Tracts in Theoretical Computer Science, Cambridge University Press,
Cambridge, MA.
-
Kay, Martin, 1980
- Algorithmic Schemata and Data Structures in Syntactic
Processing. Technical Report CSL-80-12, Xerox Palo Alto Research Center.
-
Zajac, Remi, 1998
- Feature Structures, Unification and Finite-State Transducers.
In: FSMNLP'98, International Workshop on Finite State Methods in
Natural Language Processing,
Ankara, Turkey, 1998.