
- Introduction
Persian, also known as Farsi, is the official language of Iran. It is also one of the two main languages spoken in Afghanistan, and the main language in Tajikestan, a formal central Asian republic of Soviet Union. The Persian spoken in these three countries has been influenced by the local environments. This is especially true in Tajikestan since it was isolated from the other Persian speaking countries during the Soviet era. The Persian in this country has many Russian borrowings and also uses the Russian alphabet. The language described here is mainly the Persian spoken in Iran.
This document is an overview of Persian, with an emphasis on some of the interesting aspects for a computational analysis of written text in this language.
- Background
History
Persian is derived from Indo-Iranian, one of the branches of the Indo-European languages. Indo-Iranian split into the Iranian languages and the Indo-Aryan (Indic) languages, from which most languages of India are derived. This split is estimated to have taken place around 1500 BC. The major Iranian languages are Persian, Kurdish, Pashto and Baluchi.
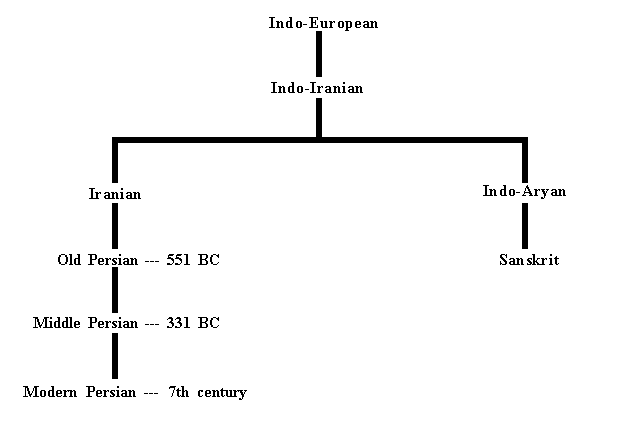
Although Persia was inhabited by the first millennium BC, the first inscriptions of Old Persian were obtained at approximately 551 BC, at the beginning of the Achemenides Empire. Old Persian had a complex morphology with a rich case and agreement system. By 331 BC (at the time of the conquest of Persia by Alexander the Macedonian) the language had simplified and had lost most of its cases and agreements. At this level of development, the language is known as Middle Persian. Modern Persian dates from the 7th century, marking the Arabic conquest of Persia.
Alphabets
 From Rishe Shenasi [Etymology]
From Rishe Shenasi [Etymology]
Arabic Influence
The Arabic conquest of Persia lasted for four centuries, from the 7th to the 11th AD. Arabic became the language of the intellectuals: Writers, poets and philosophers, as well as people in the administration, spoke and wrote in Arabic. During this period, many Arabic words were imported into the Persian language. More recently, there has been an Islamic resurgence in Iran since the revolution of 1979, and a considerable number of new Arabic borrowings are being used in Persian writing, which have also been added to the lexicon of the language. For a computational analysis of Persian, all these "new" Arabic loans have to be included in the dictionary.
Arabic has had an extensive influence on the Persian lexicon, but it has not really affected the structure of the language. Although a considerable portion of the lexicon is derived from Arabic roots, including the Arabic plural patterns, the morphological process used to obtain these lexical elements has not been imported into Persian and it is not productive in the language. The examples below show how the Arabic root system is used to derive nouns by inserting certain vowel patterns in the blank slots in the root template. (The transliteration used is described in the Appendix.)
- Root Form
| k_t_b |
- Some words derived from the Root Form
| ketâb | "book" | ||
| kotob | "books" | ||
| katbi | "written" | ||
| katib | "scribe" | ||
| maktab | "(primary) school" |
These Arabic words have been imported and lexicalized in Persian. So, for instance, the Arabic plural form for ketâb is kotob obtained by the root derivation system. In Persian, the plural for the lexical word ketâb can be given as in Arabic (kotob), or it can be obtained by just adding the Persian plural morpheme (ketâb+hâ --> ketâbhâ). Any new Persian words, however, can only be pluralized by the addition of the plural morpheme since the Arabic root system is not a productive process in Persian. In addition, since the plurals formed by the Arabic morphological system constitute a small portion of the Persian vocabulary (about 5% in the Shiraz corpus), it is not necessary to include them in the morphology; they are instead listed in the dictionary as irregular forms.
Writing System
Persian uses the Arabic alphabet. Texts are written from right to left.
Click for Persian alphabet

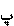
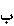
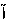
Vowels generally known as short vowels (a, e, o) are usually not written; only the long vowels (y, u, â) are represented in the text. This, of course, creates certain ambiguities. Since the short vowels are not inscribed, the word krm, for instance, can be pronounced with different vowel combinations resulting in five possible lexical elements. A reader uses the context to determine the word in the sentence.
- kerm "worm", karam "generosity", kerem "cream", krom "chrome", karm "vine"
In the Persian writing system, letters in a word are often connected to each other. Most characters have a different form depending on their position within the word. The initial form indicates that no element is attached to the element from the right (i.e., there is no "attaching" character before it, but there is one following the character). Note that an initial form does not mean that the character is in the beginning of a word, it only indicates that the character is not at the end of the word. Characters are in medial form if they have an attaching character both before and after them. The final form denotes that the character is at the end of a word. The final forms can therefore be used to mark the word boundaries.
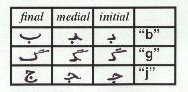
Certain characters (alef, dâl, zâl, re, ze, zhe, vâv) have only one form regardless of their position within the word.
- Word Boundaries
In written text, words are usually separated by a space. Compounds and detachable morphemes (i.e., morphemes following a word ending in final form character), however, are written without a space separating them. In other words, the two parts of a compound appear next to each other but the first element in the compound will usually end in a final form character, hence it would be possible to recognize the two parts of the compound. This format is not very consistent, however, and sometimes words can appear without a space between them. If the first word ends in a character that has a final form, then we can easily distinguish the word boundary. But if the first word ends in one of the characters that have only one form, the end of the word is not clear. Although this latter case is usually avoided in written text, it is not rare. Furthermore, a space is sometimes inserted between a word and the morpheme. In such cases, the morpheme needs to be reattached (or the space eliminated) before proceeding to the morphological analysis of the text.
- Ambiguities in Morphology
Persian morphology is affixal, consisting of a few prefixes and mostly suffixes. There are no case morphemes or definite markers, but the language has an indefinite marker, several plural morphemes and pronoun clitics, and an enclitic form for the copula. Certain ambiguities arise in a morphological analysis of written text because different morphemes have the same surface form. This, combined with the fact that the short vowels are not written, give rise to a few parallel analyses of inflected words.
This is illustrated in the example below. The word written as mrdy could be pronounced with either the /a/ or the /o/ vowels as shown. Additionally, the suffix y can fulfill different functions. The resulting interpretation for mrdy is five-way ambiguous as shown. (The "enclitic" mentioned in the second interpretation is a clitic that links the noun to a relative clause and is not translatable.)
example:
the suffix y
- mrdy
| 1.mardy | "a man" | Noun+Indefinite marker | |||
| 2.mardy | "a/the man" | Noun+Relative clause linking enclitic | |||
| 3.mardy | "you are a man" | Noun+Copula (2nd, singular) | |||
| 4.mordy | "you died" | Verb(past)+2nd, sing. inflection | |||
| 5.mardy | "manliness" | Noun+derivational morpheme |
- Light Verb Constructions
These constructions consist of an element (noun, adjective or preposition)
followed by a light verb such as the verbs "do", "give" or "hit". In these
structures, the verb has lost its original meaning. Instead, it has joined the
other element and has formed a new verb. The meaning of a
light verb construction is noncompositional; in other words, it can not be obtained by translating each element
separately as the examples illustrate:
zamyn xordan
"floor eat"
to fall
fekr kardan
"thought do"
to think
dust dâshtan
"friend have"
to like/love
gush dâdan
"ear give"
to listen
jâru zadan
"broom hit"
to sweep
This is reminiscent of the light verb constructions such as "to give an
ear" in Old English, and "to make an announcement" or "to catch a cold" in
contemporary English. These structures, however, are extremely productive
in Persian. New verbs are formed following this pattern such as
email zadan
"email hit"
to (send) email
klik kardan
"click do"
to click
(on a mouse)
In addition, verbs in simple form have been and currently are in the process of dying out and are being transformed into the light verb constructions.
If these verbs always appeared as one single unit, they could easily be
recognized. In other words, it would have been more straightforward if
the preverbal element and the light verb were to be considered as a
light verb construction each time they appeared next to each other,
and if they were
to be treated as two distinct units whenever they appeared separated in the
sentence. This is not the case, however. These verbal constructions can
be separated from each other by other intervening elements. Syntactic
analysis is needed to determine whether the element and the light verb
should be treated as a unit or as two separate entities. This is shown in
the examples below:
jâru
xvb
myzad
broom
good
was hitting
"he/she used to sweep well"
jâru
râ
zad
broom
OBJ
hit
"he/she hit the broom"
In the first case, jâru and the light verb form a light verb construction with the meaning "to sweep", even though the two elements are separated by an intervening word. In the second instance, jâru and zad are separated by the specific object marker râ but remain as distinct units, and the verb maintains its original meaning of "hitting"; no light verb construction is formed.
- Syntax
Phrase Boundaries
One of the main problems in a computational analysis of written text in Persian is determining phrase boundaries, especially the boundaries of Noun Phrases (henceforth NP).
-
No Cases
Determining phrase boundaries is difficult since Persian is a verb final language but there are no markers or cases to distinguish the Subject or the Objects in a sentence (with the exception of the specific object marker râ). The resulting structure is then
- Subject Object Verb
or - Subject Predicate Copula
-
No Phrase-Internal Markers
For instance, in English, the 's in John's book indicates that the word John is linked to book. In the example shown, the ezafe is not written between the words (although it is pronounced in spoken language) and there is no indication that the elements are related to each other within this NP.
- ketâb syâh rezâ [pronounced: ketâb-e syâh-e rezâ]
- book black Reza
- `Reza's black book'
-
Boundary Ambiguity
The example below illustrates a sentence with a Prepositional Phrase, followed by a Subject, a Predicate and the Copula. The syntactic parser will have to determine the phrase boundary for the NP within the Prepositional Phrase, as well as the boundaries for the Subject and the Predicate NPs.

Translation:
"According to the chief of the Center of Unexpected Events of the provincial government of Khorasan, the center of yesterday's earthquake was the city of Kermanshah."In spoken language, the ezafe (the short vowel) is present to link the various constituents within the Noun Phrase. When there is no ezafe pronounced, the phrase boundary is defined; the absence of the ezafe indicates the end of an NP. In this written example, however, the ezafe is not marked at all. The result is a set of 12 elements which could all belong to an NP. A word by word translation of these 12 nouns and adjectives into English gives the following:
saying chief center events unexpected provincial government Khorasan center earthquake yesterday city Kermanshah
And the phrase boundaries should be as indicated below with a
slash:
saying chief center events unexpected provincial government Khorasan
/center earthquake yesterday / city Kermanshah /
Without any clear markers to determine the phrase boundaries, and without the ezafe to link the phrase constituents, how can we distinguish the end of a phrase?
-
NP Structure
If we study the Noun Phrase structure in Persian, we can see that the Pronouns and the Indefinite Morphemes are always the last elements in the NP. In addition, the Proper Names are almost always at the end of an NP as well. Going back to the previous example, we can see that two of the phrase boundaries do in fact occur right after the two Proper Names in the sentence: Khorasan and Kermanshah.
If the ezafe morpheme is available in the text (e.g., after the vowels /A/ and /u/), it will indicate that a boundary can not occur between the element on which the ezafe appears and the following word, since the ezafe shows that these two elements are linked to each other. So, in the example shown below, no boundary can appear between nyru and havA, or havA and artesh.
| nyru-ye | havâ-ye | artesh | irân | |
| force-EZ | air-EZ | army | Iran |
| "the air force of the army of Iran" |
To sum up, a boundary should be inserted after pronouns, indefinite markers, and proper names, and no boundary is inserted following an element with an ezafe marker. If none of these elements appears in a text, however, means other than syntactic analysis or morphology should be used in order to determine the phrase boundaries.